Retrieval Augmented Generation with Amazon Bedrock
Before diving into the RAG workflow, it’s important to understand embeddings. Embeddings represent documents as vectors in a multi-dimensional space. These vectors capture the essence of the content in a format that machines can process. By converting text into embeddings, we enable computers to “understand” and compare different text passages based on their contextual similarity.
Embedding Visualization
Once embeddings are generated, the next step is to store and organize them for efficient retrieval. This is where vector databases come into play. A vector database allows us to store and query embeddings, facilitating fast and relevant retrieval of documents based on their vector representation. Essentially, it serves as a bridge between raw data and actionable insights derived from large language models (LLMs). For this module, we’ll use FAISS.
️ Powering RAG with Amazon Bedrock
With the foundation of embeddings and vector databases in place, we are ready to implement the RAG workflow using Amazon Bedrock. This section demonstrates how to use large language models to process input queries, retrieve relevant document embeddings from a vector database, and generate coherent, contextually appropriate responses using LLMs. We’ll also leverage LangChain, a framework designed to simplify building LLM-powered applications.
Exercise 1: Getting Started with RAG
Open rag_examples/base_rag.py. Let’s walk through the code to see how RAG works.
We start with a list of example sentences (line 15):
sentences = [
# Pets
"Your dog is so cute.",
"How cute your dog is!",
"You have such a cute dog!",
# Cities in the US
"New York City is the place where I work.",
"I work in New York City.",
# Color
"What color do you like the most?",
"What is your favorite color?",
]
Now let’s look at the implementation of the RAG workflow in rag_with_bedrock (line 60)
- Create Bedrock Embeddings We initialize the embedding function by calling BedrockEmbeddings. We’re using the Amazon Titan text embedding model to convert text into a vector format for similarity comparison.
embeddings = BedrockEmbeddings(
client=bedrock_runtime,
model_id="amazon.titan-embed-text-v1",
)
- Vector Search with FAISS We create a local vector store using FAISS.from_texts, which indexes the sentence embeddings into a searchable vector database. We can then vectorize a query and retrieve similar documents.
local_vector_store = FAISS.from_texts(sentences, embeddings)
docs = local_vector_store.similarity_search(query)
- Calling the RAG Prompt: We compile the content of the retrieved documents to form a context string. We then create a prompt that includes the context and the query. Finally, we call the call_claude function with our prompt get our answer.
for doc in docs:
context += doc.page_content
prompt = f"""Use the following pieces of context to answer the question at the end.
{context}
Question: {query}
Answer:"""
model_id = "us.amazon.nova-lite-v1:0"
system_prompts = [{"text": "You are a helpful AI"}]
message_1 = {
"role": "user",
"content": [{"text": f"{prompt}"}],
}
messages = [message_1]
result = generate_conversation(model_id, system_prompts, messages)
return result
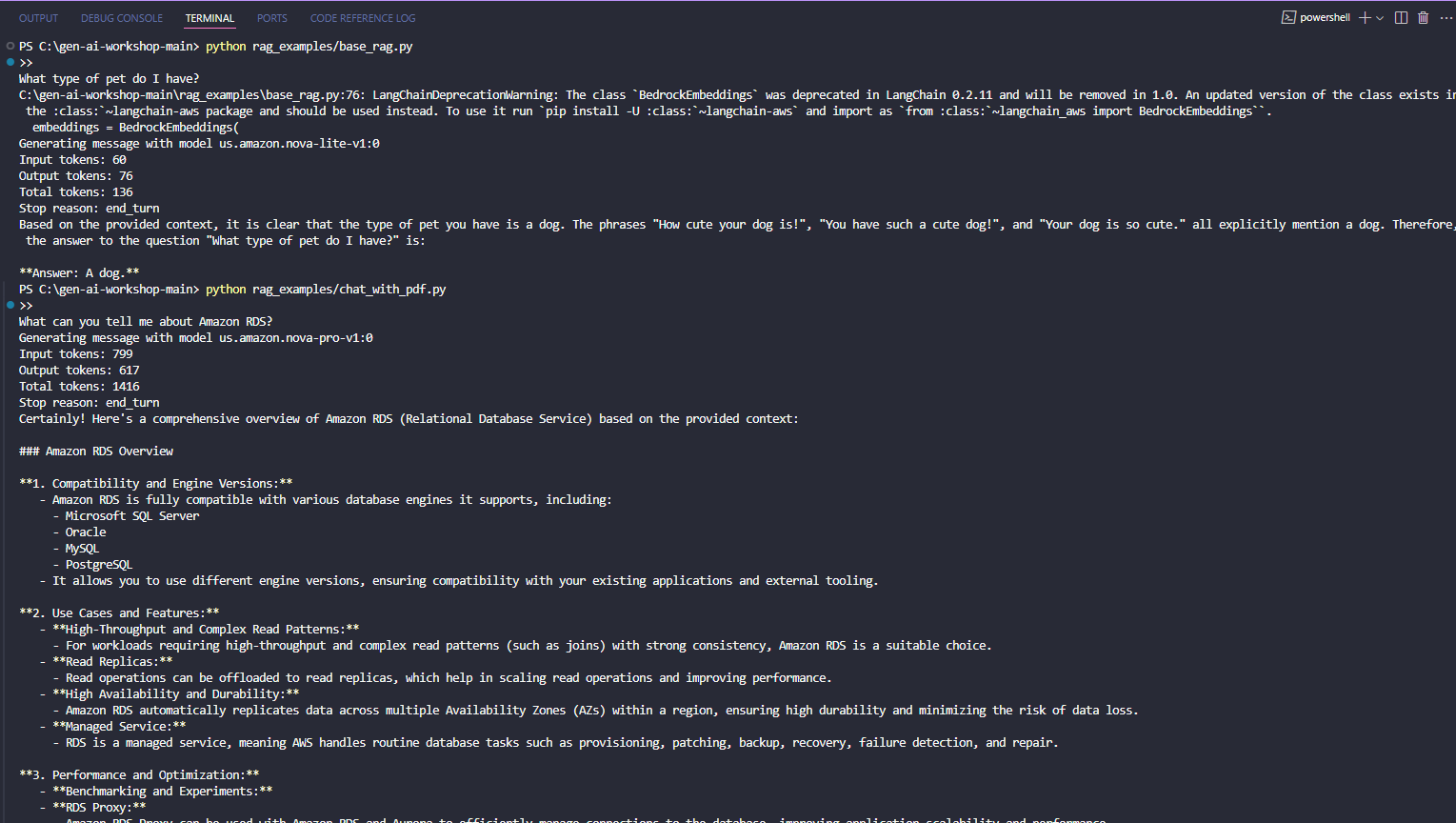
To test the code, run:
python3 rag_examples/base_rag.py
Try changing the query at line 109. For example:
- try
What city do I work in?
Exercise 2: Chat with a PDF
There is also an example of how you chat with a PDF. Inside rag_examples/chat_with_pdf.py we have the chunk_doc_to_text function that will ingest the PDF and chunk every 1000 characters to store in the vector database. This process can take a while depending on the server, so we have already chunked the data which is stored in the folder local_index.
In this example we stored all the text from the AWS Well Architected Framework which highlights best practices for designing and operating reliable, secure, efficient, cost-effective, and sustainable systems in the cloud.
Now try running the code by entering the following command in the Terminal and pressing enter:
python3 rag_examples/chat_with_pdf.py
You can change the query on line 123. Play around to see how the model is able to use the context to figure out the correct answer. For example try:
What are some good use cases for non-SQL databases?What is the Well-Architected Framework?How can I improve security in the cloud?
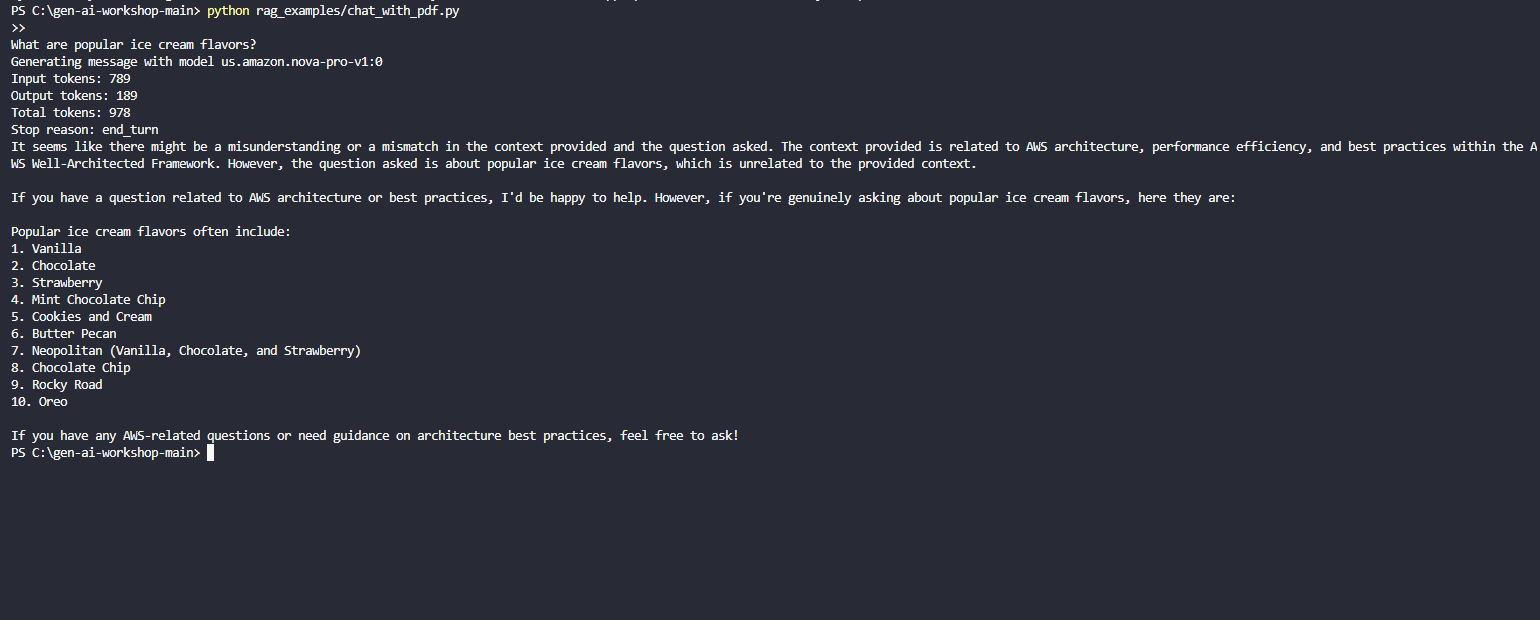
You can even try off-topic questions such as what are popular ice cream flavors to see how the model handles questions outside the context.
Wrap up
Now that you have gotten a taste of using Amazon Bedrock for RAG, let’s explore how we can create scalable RAG workflows.